인덱스
인덱스는 테이블의 조회 속도를 높여주는 역할을 한다.
즉, 조건에 만족하는 레코드를 빠르게 조회하기 위해서 인덱스를 사용한다.
또한 빠르게 정렬을 하거나 그룹핑을 하기 위해서도 사용한다.
인덱스가 없다면, full scan이 발생하고 시간복잡도는 O(N)이 된다.
인덱스가 걸려있다면, full scan보다 빠르게 조회가 가능하며 시간복잡도는 O(logN)이다. (B-tree 기준)
인덱스의 종류: B-Tree 인덱스, Hash 인덱스, Fractal 인덱스, BRIN 인덱스, GIN 인덱스 등
페이지(블럭)
디스크와 메모리(버퍼풀)에 데이터를 읽고 쓰는 최소 작업 단위로,
PK와 테이블 등은 모두 페이지 단위로 관리된다.
쿼리로 하나의 레코드를 읽고 싶어도 하나의 블록을 읽어야 하는 것이다.
디스크 I/O를 통해서 페이지를 읽어오면 버퍼풀이라는 메모리에 캐싱을 해두게 된다. 페이지에 저장되는 데이터의 크기가 클수록 디스크 I/O가 많아질 수 있고, 메모리에 캐싱할 수 있는 페이지의 수가 줄어들 수 있다.
따라서 DB 성능 개선 혹은 쿼리 튜닝은 디스크 I/O 자체를 줄이는 것이 핵심인 경우가 많다.
페이지에 저장되는 개별 데이터의 크기를 최대한 작게 해서 1개의 페이지에 많은 데이터를 저장할 수 있도록 하는 것이 중요하다.
인덱스로 데이터 조회
인덱스는 페이지 단위로 저장되며 인덱스 키를 바탕으로 항상 정렬된 상태를 유지한다.
인덱스는 테이블과 독립적인 저장공간으로 데이터를 조회하는 순서는 아래와 같다.
1) 인덱스를 통해서 PK를 찾음
2) PK를 통해서 레코드를 찾음
인덱스를 통해서 레코드 1건을 읽는 것이 4~5배 정도 비싸서 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어간다면 인덱스를 이용하지 않는 것이 효율적이다.
인덱스에 영향을 주는 요소
- PK 크기
- 인덱스 컬럼 순서: 다중 컬럼 인덱스 순서
- 카디널리티: 값이 유니크할 수록 처리가 빠름
- 인덱스 정렬 순서 및 스캔방향
B-Tree 인덱스
B-Tree 구조는 자식 노드를 2개만 갖는 이진 트리를 확장해서 N개의 자식을 가질 수 있도록 고안한 방식이다.
항상 균형 트리를 유지하는 자료 구조를 이용하고 핵심은 "균일성"이다.
최상위에는 단 하나의 노드가 존재하는데 이는 Root Node라고 하며 중간 노드는 Branch Node, 최하위 노드를 Leaf Node라고 한다. Leaf Node에 도달하면 ( index, PK ) 쌍으로 저장이 되어있다.

최악의 경우에도 시간복잡도가 O(log N)이다.
인덱스를 적용하는 컬럼의 값을 변형하지 않고 원래의 값을 이용한다.
‘=’ 과 같은 값 자체에 대한 탐색에 효과적이다.
B-Tree 인덱스 특성상 LIKE를 통한 검색은 ‘검색어%’만 인덱스를 활용할 수 있고 ‘%검색어%’ 연산과 같은 경우 인덱스가 적용되지 않는다.
검색은 100%일치 또는 값의 앞부분만 일치하는 경우 ( e.g LIKE '%something' ) 사용할 수 있다.
LIKE ‘%something%’과 같은 경우에는 인덱스가 적용되지 않는다.
또한 인덱스의 키 값에 변형이 가해진 경우는 B-Tree에 존재하는 값이 아니므로 B-Tree를 사용할 수 없다. ( e.g. something_index+1 > 100 )
또한 B-Treee 인덱스는 짧은 문자열이나 숫자 타입에서 효과적인 반면 text 타입 등의 대량 문자열은 효과적이지 못하다.
검색할 때 B-Tree는 자주 접근되는 노드를 루트 노드 가까이에 배치할 수 있으며 루트노드에서 가까울 경우 브랜치 노드에도 데이터가 존재해서 빠르다.
PostgreSQL INDEX
// 인덱스 조회
SELECT * FROM pg_indexes WHERE tablename = '테이블명';
// 인덱스 설정
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명)
// multi-column 인덱스 설정
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명1, 컬럼명2)
// 인덱스 삭제
DROP INDEX 인덱스명;
- 기본적으로 설정되어있는 index

- 인덱스 추가

- 기본적으로 B-Tree 방식으로 설정된다
INDEX 적용 및 성능 비교
Cost: 특정 작업이 다른 작업들에 비해 몇 배의 비용이 드는가를 기준으로 계산한 비용
(cost=Startup Cost..Total Cost)
Startup Cost: 첫 번째 row를 출력할 때까지의 시간과 비용을 의미함
Total Cost: query node에서 데이터를 읽기 시작할 때부터 모든 row를 출력할 때까지의 전체 시간/비용을 의미
Case 1. 완전히 동일한 값을 조회할 경우
- 인덱스 설정 전

cost = 0.00..1606.20
Startup Cost: 첫 번째 row를 출력할 때까지 0.00의 시간/비용
Total Cost: 모든 row를 출력할 때까지의 1606.20의 시간/비용
- 인덱스 설정 후

cost = 0.41..8.43
Startup Cost: 첫 번째 row를 출력할 때까지 0.41의 시간/비용
Total Cost: 모든 row를 출력할 때까지의 8.43의 시간/비용
=> 인덱스를 설정한 후 cost가 현저히 적다는 것을 알 수 있다.
Case 2. Like '% %' 값을 조회할 경우
- 인덱스 설정 전
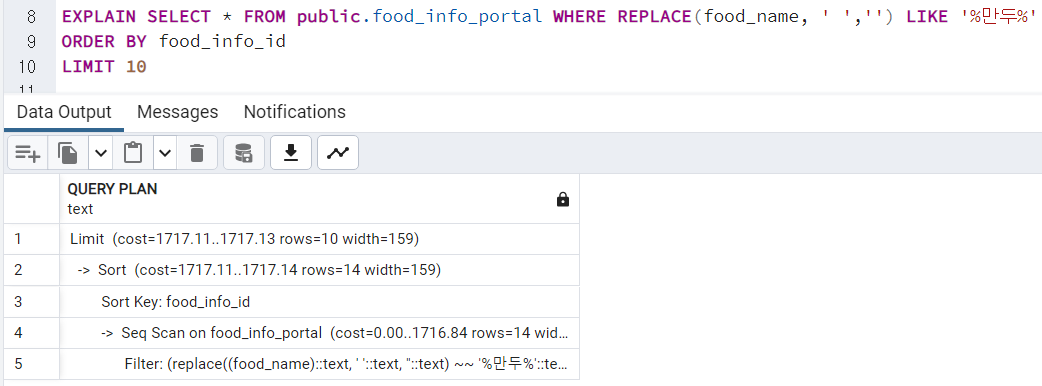

- 인덱스 설정 후


B-Tree 인덱스로 적용하자 차이가 없었다.
B-Tree는 LIKE '%something%'의 경우가 적용되지 않기 때문이다.
이를 해결하기 위해 PostgreSQL에서는 pg_bigm 모듈을 활용할 수 있다.
( pg_bigm 모듈 공부 중)
Index가 좋다면, 마구 만들어도 괜찮을까?
인덱스를 위한 부가적인 데이터들도 생성됨
table에 write(INSERT, UPDATE, DELETE)를 할 때마다 index도 변경
추가적인 저장 공간을 차지
-> 불필요한 index는 만들지 않는 것이 좋음
Covering Index
조회하는 arrtibute를 index가 모두 cover하는 경우를 말하며 index 만으로도 조회가 가능해서 조회 성능이 더 빠르다.
참고자료
https://mangkyu.tistory.com/286
https://chiefcoder.tistory.com/67
https://overcome-the-limits.tistory.com/856
https://zorba91.tistory.com/293
https://seunghyunson.tistory.com/20
https://developerhjg.tistory.com/215
'IT Study > DB' 카테고리의 다른 글
| [Programmers SQL] WITH RECURSIVE문 (1) | 2024.10.22 |
|---|---|
| [DB] 트랜잭션 (feat. nest.js, PostgreSQL) +에러해결 (0) | 2024.01.26 |
| [TypeORM] QueryBuilder | SELECT 절에서 as 사용하기 (with. getMany vs getRawMany) (0) | 2024.01.24 |
| [SQL] 데이터조작어(DML) (Feat. Elice 12주차) (0) | 2023.11.11 |
| [SQL] 제약조건 추가 및 삭제 쿼리 (Feat. Elice 12주차) (0) | 2023.11.07 |