Apache Software Foundation에서 설계한 다양한 아키텍처들이 존재한다.
그 중에서 대용량 데이터 처리에 많이 사용되는 엔진인 Apache Spark에 대해 알아보겠다
Apache Spark
Apache Spark™ - Unified Engine for large-scale data analytics
Run now Install with 'pip' $ pip install pyspark $ pyspark Use the official Docker image $ docker run -it --rm spark:python3 /opt/spark/bin/pyspark QuickStart Machine Learning Analytics & Data Science df = spark.read.json("logs.json") df.where("age > 21").
spark.apache.org
- 대용량 데이터 처리에 최적화된 오픈 소스 분산 컴퓨팅 시스템
- 분산 데이터 처리 엔진으로, 배치 처리를 위해 설계
- 메모리 내 처리 기능을 통해 기존 하둡 기반 시스템보다 빠른 처리 속도를 자랑
- Spark 스트리밍 모듈이라고, 기본 분산 아키텍처에 스트림 처리 기능 추가
- 데이터 전환 및 일괄 처리 워크플로우를 지원하는 순차 계층이 있는 분산형 기본-보조 아키텍처를 사용
Spark의 핵심 특징
1. 메모리 내 데이터 처리 능력으로 빠름
- 메모리 내 처리를 통해 디스크 기반 처리보다 빠른 속도로 데이터 분석이 가능
- 하둡보다도 빠른 속도를 보임
2. 사용의 용이성
- Scala, JAVA, Python 등 다양한 프로그래밍 언어를 지원
3. 다양한 데이터 소스에서 데이터 읽어올 수 있음
- SQL 쿼리, 스트리밍 데이터 처리, 복잡한 알고리즘을 통한 분석 가능
4. API와 라이브러리, 저장소 제공으로 쉽게 작업 수행 가능
5. Spark를 설치하면 하둡도 자동으로 설치됨
* 하둡
분산 파일 시스템. 여러 대의 컴퓨터 클러스터에서 대규모 데이터 베트를 분산처리할 수 있게 해주는 프레임워크.
Spark 구조
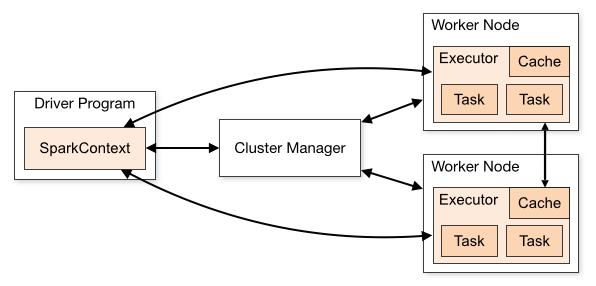
- 크게 두 가지로, 작업을 관리하는 Driver와 작업이 실행되는 노드를 관리하는 Cluster Manager로 볼 수 있다.
- Driver Program
- Spark Job을 작성해서 제출하면, 전체 spark를 관장. 마스터 같은 역할을 함
- main 함수를 실행하고 SparkContext 객체를 생성
- SparkContext
- Cluster Manager와 연결되는 객체로 마스터 역할을 하는 라이브러리
- Job을 나눠 가지게 해서 각 Worker node에 나눠서 전달해줌
- Cluster Manager
- Driver와 Executor 프로세스로 실행되는 Spark Application의 리소스를 효율적으로 배분
- Node가 얼마나 여유로운지, job을 얼마나 받을 수 있는지 등을 확인하며 Driver도 보고 Worker Node도 보며 정보 처리
- yarn, Mesos, StandAlione 등이 Cluster Manager를 지원
- Cluster Manager와 SparkContext가 연결되면 각 클러스터 내부의 워커노드에서 Executor를 얻게 됨
- Executor
- Task를 실행하는 객체
- 실제 작업을 진행하는 Process Executor가 task 단위로 작업을 실행하고 결과를 Driver에 알려줌
- 사용자가 만든 SparkContext를 위해 데이터를 저장하거나 연산을 실행하는 프로세스
- Task
- job, stage, task로 구성
- job: Spark Application한테 전달한 작업
- stage: 단위에 따라서 구분한 작업
- task: Executor에서 실행되는 실제 작업
- Spark는 Diriver가 하나, 여러개의 Worker Node로 구성
- SparkContext에서 HDFS를 사용해서 파일을 쪼개서 클러스터에 뿌려줌
Spark 핵심 구성요소
- RDD (Resilient Distributed Dataset)
- 분산 데이터의 컬렉션을 추상화한, 분산 데이터 모델
- MapReduce와 비슷한 역할을 하며 어떻게 데이터를 처리할 것인지 How를 기술함
- Spark가 효율적인 데이터 처리를 가능하게 하는 기반이 됨
- DAG (Directed Acyclic Graph)
- 작업의 종속성을 파악하여 최적의 처리 경로를 결정
다음에는 RDD를 구제척으로 살펴보며 각종 API와 DataFrame과의 차이에 대해서 공부 해보겠다
https://spark.apache.org/docs/latest/cluster-overview.html
https://aws.amazon.com/ko/compare/the-difference-between-kafka-and-spark/